How to: Copy delimited files having column names with spaces in parquet format using ADF
Delimited files which have column names with spaces cannot directly be ingested in parquet format using the Azure Data Factory’s copy activity. We encounter the following error:
Failure type: User configuration issue
Details: ErrorCode=ParquetInvalidColumnName,'Type=Microsoft.DataTransfer>common.Shared.HybridDeliveryException,Message=The column name is invalid. Column name cannot contain these character:[,;{}()\n\t=],Source=Microsoft.DataTransfer.Common,'
So,if the column names of file to be ingested have any of the characters mentioned above, the copy activity fails to convert delimited files to parquet.
There are two ways to overcome this problem both of which involve leveraging dynamic mapping option of the Copy Activity. One has been explained in detail in a video by WafaStudies. Click on this link to view it. Although this solution provides more flexibility, it requires us to maintain a mapping table which is a manual effort for each type of file. If we call a stored procedure to auto-generate our mapping script, it does eliminate our manual effort but requires us to connect to Synapse or the database being used to run our script.
The other route to this problem, which will be discussing in detail here, is to generate the mapping JSON script within ADF, without using Data Flow. So no additional infrastructure has to be set-up.
Below is the complete JSON script of the pipeline for you to have a look into the minute details:
{
"name": "csv_dynamic_mapping_copy",
"properties": {
"activities": [
{
"name": "Set_header_names",
"type": "SetVariable",
"dependsOn": [
{
"activity": "Lookup_file",
"dependencyConditions": [
"Succeeded"
]
}
],
"userProperties": [],
"typeProperties": {
"variableName": "header_names",
"value": {
"value": "@split(replace(replace(string(activity('Lookup_file').output.firstRow),'{',''),'}',''),'\",\"')",
"type": "Expression"
}
}
},
{
"name": "Lookup_file",
"type": "Lookup",
"dependsOn": [],
"policy": {
"timeout": "7.00:00:00",
"retry": 0,
"retryIntervalInSeconds": 30,
"secureOutput": false,
"secureInput": false
},
"userProperties": [],
"typeProperties": {
"source": {
"type": "DelimitedTextSource",
"storeSettings": {
"type": "AzureBlobFSReadSettings",
"recursive": true,
"enablePartitionDiscovery": false
},
"formatSettings": {
"type": "DelimitedTextReadSettings"
}
},
"dataset": {
"referenceName": "ds_csv_adls",
"type": "DatasetReference",
"parameters": {
"in_file_path": {
"value": "@pipeline().parameters.in_file_path",
"type": "Expression"
},
"in_filename": {
"value": "@pipeline().parameters.in_filename",
"type": "Expression"
},
"header": {
"value": "@bool('false')",
"type": "Expression"
}
}
}
}
},
{
"name": "Copy data1",
"type": "Copy",
"dependsOn": [
{
"activity": "Set_mapping_script",
"dependencyConditions": [
"Succeeded"
]
}
],
"policy": {
"timeout": "7.00:00:00",
"retry": 0,
"retryIntervalInSeconds": 30,
"secureOutput": false,
"secureInput": false
},
"userProperties": [],
"typeProperties": {
"source": {
"type": "DelimitedTextSource",
"storeSettings": {
"type": "AzureBlobFSReadSettings",
"recursive": true,
"enablePartitionDiscovery": false
},
"formatSettings": {
"type": "DelimitedTextReadSettings"
}
},
"sink": {
"type": "ParquetSink",
"storeSettings": {
"type": "AzureBlobFSWriteSettings"
},
"formatSettings": {
"type": "ParquetWriteSettings"
}
},
"enableStaging": false,
"translator": {
"value": "@json(variables('mapping_script'))",
"type": "Expression"
}
},
"inputs": [
{
"referenceName": "ds_csv_adls",
"type": "DatasetReference",
"parameters": {
"in_file_path": {
"value": "@pipeline().parameters.in_file_path",
"type": "Expression"
},
"in_filename": {
"value": "@pipeline().parameters.in_filename",
"type": "Expression"
},
"header": {
"value": "@bool('true')",
"type": "Expression"
}
}
}
],
"outputs": [
{
"referenceName": "ds_parquet_adls",
"type": "DatasetReference",
"parameters": {
"out_file_path": {
"value": "@pipeline().parameters.out_file_path",
"type": "Expression"
},
"out_filename": {
"value": "@pipeline().parameters.out_filename",
"type": "Expression"
}
}
}
]
},
{
"name": "ForEach_element_in_header_names",
"type": "ForEach",
"dependsOn": [
{
"activity": "Set_header_names",
"dependencyConditions": [
"Succeeded"
]
}
],
"userProperties": [],
"typeProperties": {
"items": {
"value": "@variables('header_names')",
"type": "Expression"
},
"isSequential": true,
"activities": [
{
"name": "Set_original_header",
"type": "SetVariable",
"dependsOn": [],
"userProperties": [],
"typeProperties": {
"variableName": "original_header",
"value": {
"value": "@replace(substring(item(),add(indexOf(item(),':'),2),sub(length(item()),add(indexOf(item(),':'),2))),'\"','')",
"type": "Expression"
}
}
},
{
"name": "Set_new_header",
"type": "SetVariable",
"dependsOn": [
{
"activity": "Set_original_header",
"dependencyConditions": [
"Succeeded"
]
}
],
"userProperties": [],
"typeProperties": {
"variableName": "new_header",
"value": {
"value": "@replace(replace(trim(variables('original_header')),' ','_'),'\\t','')",
"type": "Expression"
}
}
},
{
"name": "Append_to_json_map",
"type": "AppendVariable",
"dependsOn": [
{
"activity": "Set_new_header",
"dependencyConditions": [
"Succeeded"
]
}
],
"userProperties": [],
"typeProperties": {
"variableName": "json_map",
"value": {
"value": "@json(concat('{\n\"source\": {\n \"name\": \"',variables('original_header'),'\",\n \"type\": \"string\"},\n\"sink\": {\n \"name\": \"',variables('new_header'),'\"}\n}')\n)",
"type": "Expression"
}
}
}
]
}
},
{
"name": "Set_mapping_script",
"type": "SetVariable",
"dependsOn": [
{
"activity": "ForEach_element_in_header_names",
"dependencyConditions": [
"Succeeded"
]
}
],
"userProperties": [],
"typeProperties": {
"variableName": "mapping_script",
"value": {
"value": "@concat('{\n\"type\": \"TabularTranslator\",\n\"mappings\":',replace(replace(string(variables('json_map')),'\"{','{'),'}\"','}'),'}')",
"type": "Expression"
}
}
}
],
"parameters": {
"in_file_path": {
"type": "string",
"defaultValue": "delimited-files"
},
"in_filename": {
"type": "string",
"defaultValue": "emp_data.csv"
},
"out_file_path": {
"type": "string",
"defaultValue": "output-files"
},
"out_filename": {
"type": "string",
"defaultValue": "employees.parquet"
}
},
"variables": {
"header_names": {
"type": "Array"
},
"original_header": {
"type": "String"
},
"new_header": {
"type": "String"
},
"json_map": {
"type": "Array"
},
"mapping_script": {
"type": "String"
}
},
"annotations": []
}
}
For this demonstration I used a csv file with following data:
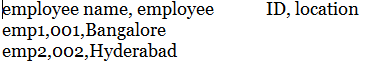
I placed this file in the Azure Data Lake Storage Gen2 and created a linked service in ADF to connect to the data store. To learn how to setup a linked service, refer this link. Then, follow the below steps:
- Setup the dataset for csv file residing in ADLS
- Setup the dataset for parquet file to be copied to ADLS
- Create the pipeline

1. Setup the source Dataset
After you create a csv dataset with an ADLS linked service, you can either parametrize it or hardcode the file location. You can refer the below images to set it up. Parameterizing it gives you the ability to feed the file path and its name through the pipeline.


2. Setup the sink Dataset
Similarly, you can setup a parquet dataset with ADLS linked service. Refer the below images:


3. Create the Pipeline
To give you a visual of the pipeline, below is an image of it.

Below are all the parameters and variable created:


Now, we will go through each activity of the pipeline.
3.1 Lookup file header
Apart from the file name and file path, we have to pass header as “False” to the source dataset and retrieve just the first row from the file.

Below is the image of the output that we get from the activity.

3.2 Set Variable (header_names)
Header_names is a variable of array type. Here, we use the output of the lookup activity and create a list with each key-value pair an element of the list. We use the split function and "," as the delimiter to avoid any complication if the header itself has commas in them. This way, it only splits the string if a comma is preceded and succeeded by double-quotes. One additional thing that we do here is replace the opening and closing braces with empty string so that we just get those key-value pairs. Below is the value set to this variable

Below is the expression used to achieve it:
@split(replace(replace(string(activity('Lookup_file').output.firstRow),'{',''),'}',''),'\",\"')
3.3 ForEach (value in the header_names list)
In this activity, we go through each element of the array created in the previous activity and extract the original header, create a new header name with the spaces, tabs and other special characters removed and append it to an array variable.

We use 3 activities inside this loop, which are:
-
Set variable (original_header) - Here, we extract the substring starting from
:, i.e., the index after the colon to the end of the string. Additionally, we remove the double-quotes that exist in the string. Below is the expression used:@replace(substring(item(),add(indexOf(item(),':'),2),sub(length(item()),add(indexOf(item(),':'),2))),'\"','') -
Set variable (new_header) - Here we use the
original_headervariable and trim it, remove tabs and other special characters and replace spaces with under-scores (_). When I created these activities, I realized that the required output can be achieved with just one activity until I tried it and came to know that self-referencing of variables is not allowed in ADF. Below is the expression used:@replace(replace(trim(variables('original_header')),' ','_'),'\\t','') -
Append variable (json_map) - In this activity, we append one JSON object at a time to the
json_maparray-type variable. Array is the only variable type that can store JSON objects in ADF. Here we create a part of the mapping script that is required in the copy activity. The structure that is required by the ADF is shown below:{ "source": { "name": "<source_column_name>", "type": "string" } "sink": { "name":"<sink_column_name>" } }The expression used to achieve this is given below:
@json(concat('{\n\"source\": {\n \"name\": \"',variables('original_header'),'\",\n \"type\": \"string\"},\n\"sink\": {\n \"name\": \"',variables('new_header'),'\"}\n}')\n)Below is an image to show one of the elements of this variable.

3.4 Set Variable (mapping_script)
This activity is used to generate the final JSON script and store it in a string-type variable mapping_script. Here, we append a few important details to our script so that ADF can recognize it as a mapping script and remove few characters from the string which arise when we concatenate an array to a string. Below is the expression:
@concat('{\n\"type\": \"TabularTranslator\",\n\"mappings\":',replace(replace(string(variables('json_map')),'\"{','{'),'}\"','}'),'}')
Below is the output of this variable:

3.5 Copy Activity
Below are the details for the source, followed by sink of the copy activity:


The important thing to note here is to pass header as True to the source dataset.
Then we can just pass the string variable mapping_script as a JSON to the Mapping section of the copy activity as shown below:

4. Output of the pipeline
The pipeline runs with 24 seconds as shown below.

The parquet file generated, has the desired header when read in Databricks as shown below:

This way you can dynamically replace spaces between column names and convert your delimited file to parquet. This pipeline can be a separate execute pipeline activity which you can call whenever you need this operation in your ETL pipeline.